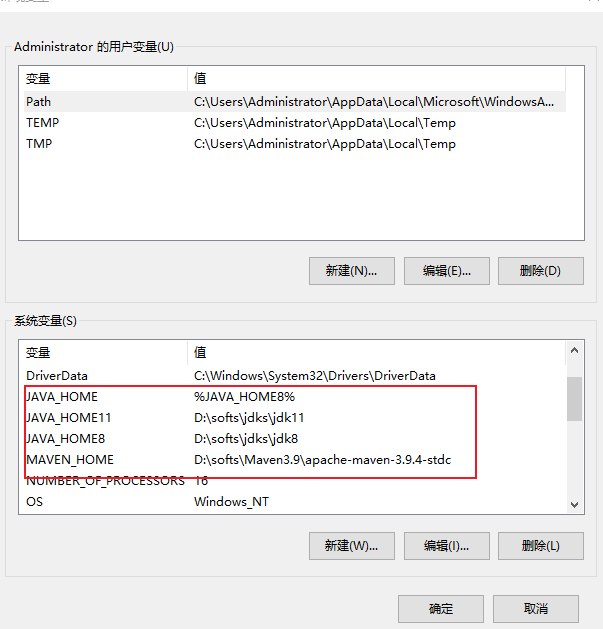
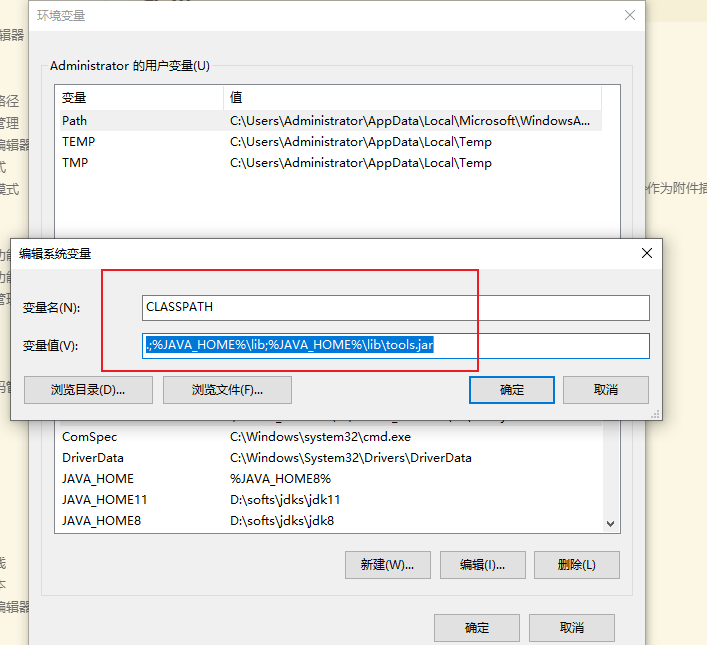
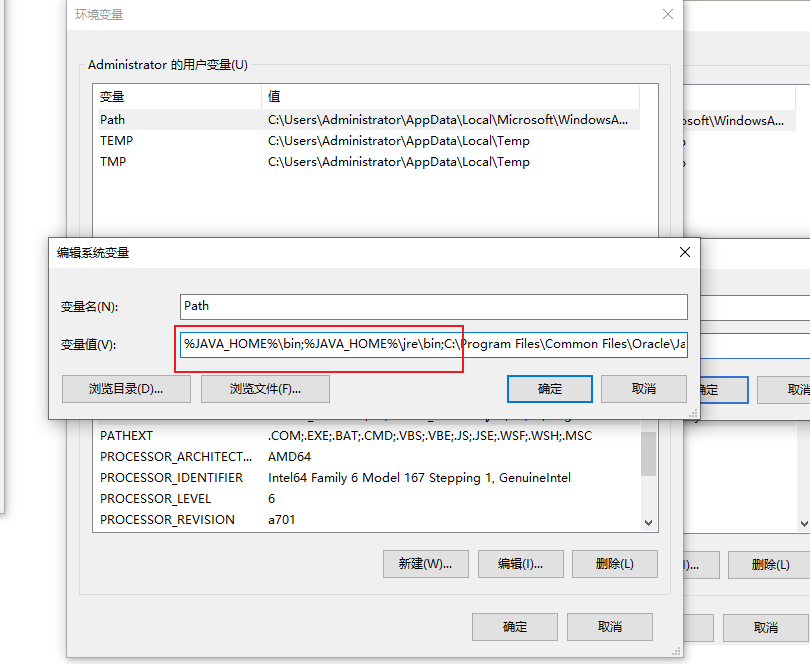
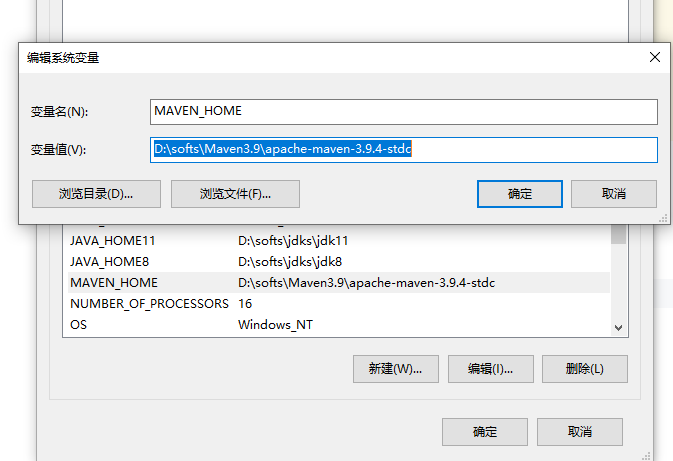

苹果日历使用设置(附上相关数据源)
设置位置
Mac:打开 日历->文件->新建日历订阅
iPhone:系统设置->密码与账户->添加账户->其他->添加已订阅的日历
订阅源信息:
中国法定节假日:
https://calendar.google.com/calendar/ical/pmbvm6f01ijruokq0spqa854u2ra71gt%40import.calendar.google.com/public/basic.ics
24节气订阅地址:
https://github.com/KaitoHH/24-jieqi-ics
中国节假日补班日历:
https://github.com/lanceliao/china-holiday-calender
老黄历:
https://github.com/zqzess/holiday-and-chinese-almanac-calendar?tab=readme-ov-file
回忆不散:QQ空间导出助手,保存你的青春记忆
前言
随着年龄的增长,我们对过去的美好时光愈加怀念。在过去的时间总有留下了一些美丽的瞬间。
在那韶华的回忆里,QQ 空间的说说、留言、相册、访客、黄钻,总有一个牵动过我们的心❤️。
虽然 QQ空间依旧还在,而我们已经不在青葱,已然日渐成熟,当年的那些人也渐行渐远,只留下一些零碎的回忆。
如今,发现了一个可以将这些回忆保存到现实中的工具——QQ空间导出助手。这款工具让我们能够在充满回忆的世界中徜徉。开发者的一段话也让我深有感触:
落叶随风,青春,稍纵即逝,QQ空间,一个承载了很多人的青春的地方。
然而,新浪博客相册宣布停止运营,网易相册关闭,QQ账号支持注销等等,无不意味着,互联网产品都有着自己的生命周期,但生命周期到了尽头,我们的数据怎么办。
数据,还是要本地备份一份的,QQ空间导出助手的谷歌扩展,可以QQ空间的日志、私密日志、说说、相册、留言板、QQ好友、视频为文件,供永久保存。
正餐
简单介绍
这是一个 QQ 空间的导出助手,能帮助解决说说、照片等的导出服务,针对大量的图片导出非常方便,并且还是原图。
可以轻松将这些珍贵的回忆保存下来,不再担心它们随互联网产品的生命周期消失。
插件下载
下载的途径有好几个:
- 谷歌商店
- GitHub 仓库
- 如果前两个途径都没有下载到,可以后台发送 20240723 获取安装包,解压进行安装。
如果是安装包的话,可以这样进行设置:
- 打开浏览器设置按钮
- 找到扩展程序
- 加载已经解压的文件
- 成功后会在标题栏中显示标识
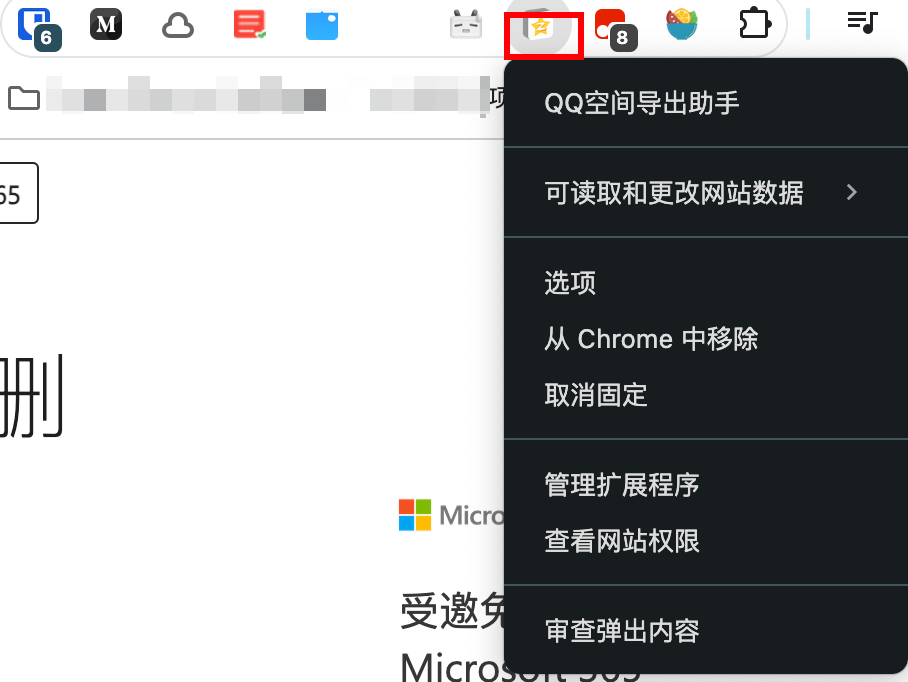
配置插件
打开小图标会显示可以进行备份的数据,这次主要是为了备份相册,所以单独选择相册。
在相册列表中选择需要进行备份的相册。
注意最后一点比较重要,一定要关闭浏览器的 下载前询问每个文件的保存位置这个选项。
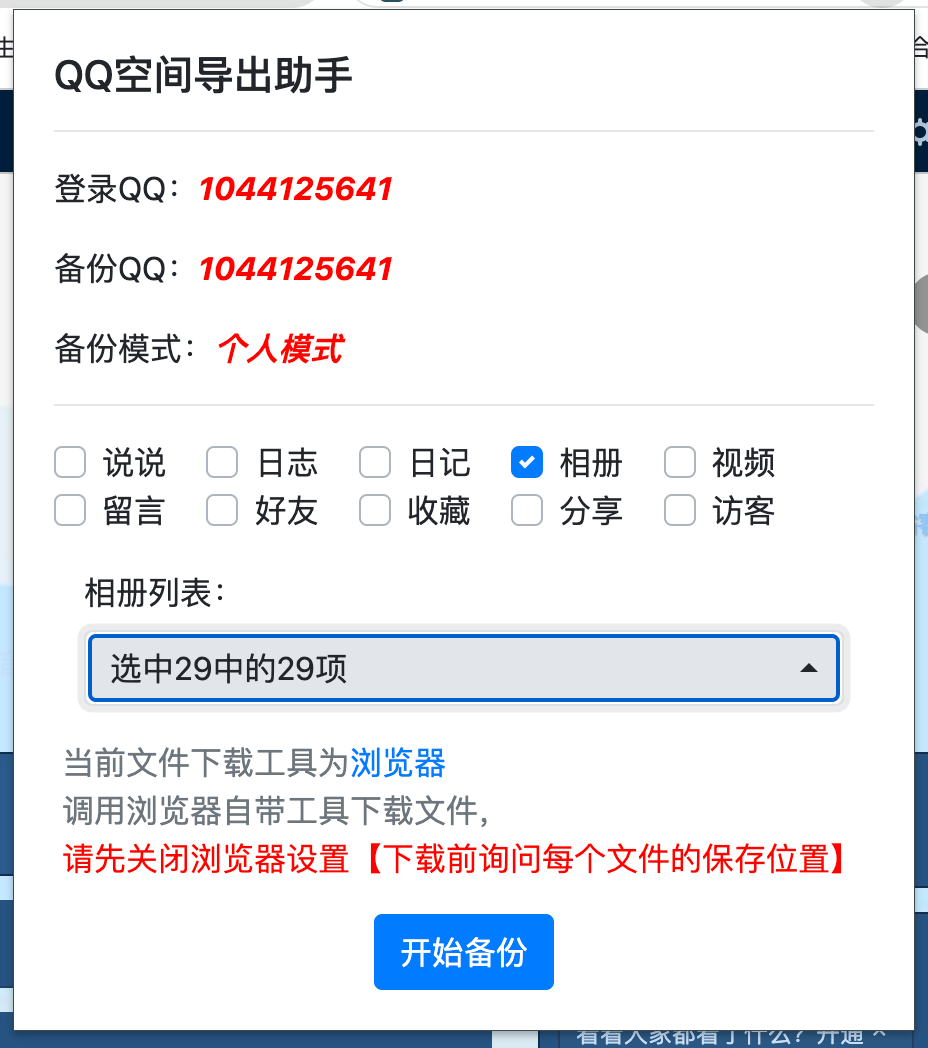
导出照片
点击开始备份以后,会显示下载进度,显示下载的数量以及一些对应的下载日志。
不出意外的话,都能成功。
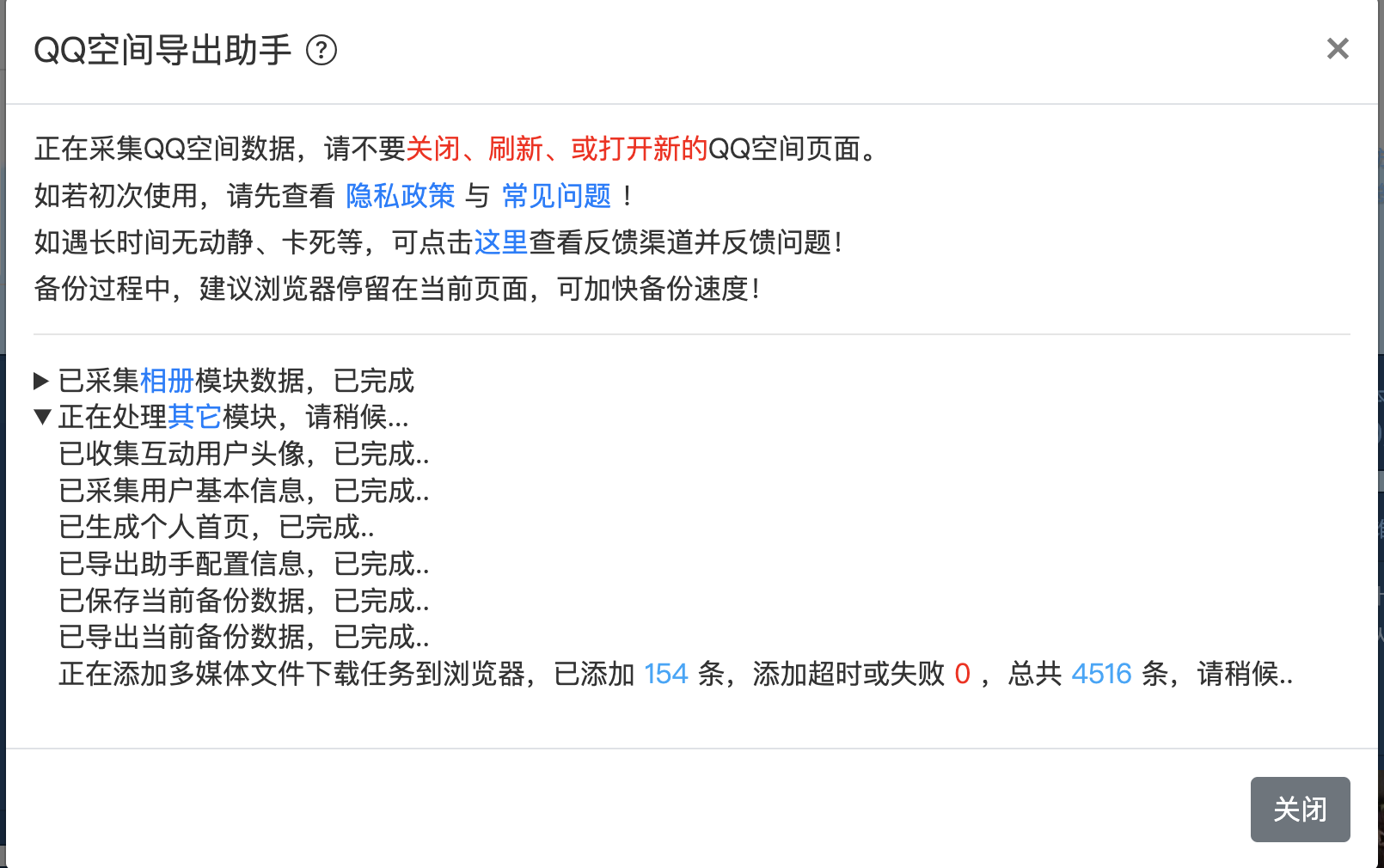
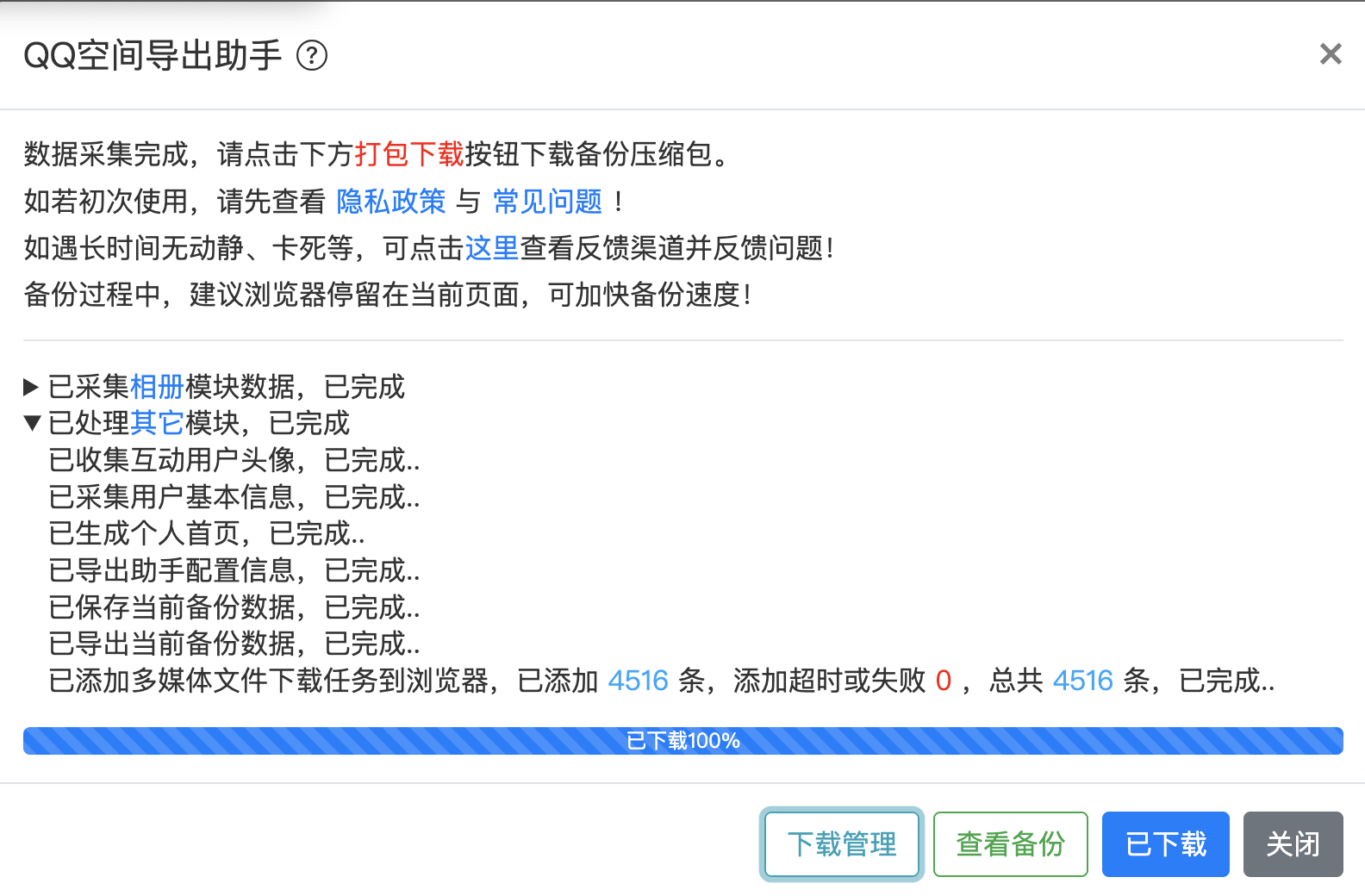
下载的进度可以实时进行查看,下载完成后会显示如下界面,然后去自己的电脑文件夹中查看下载的图片。
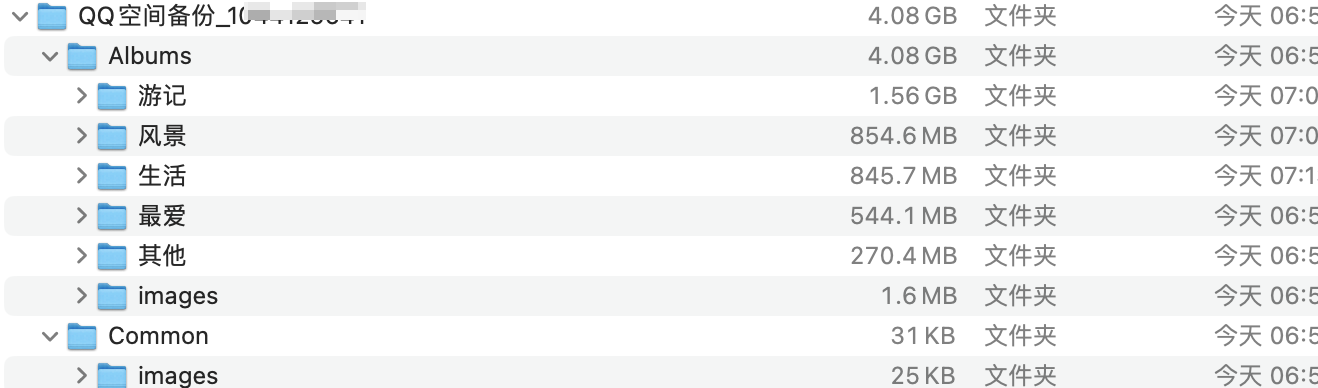
文件查看
在下载好的文件中查看图片,我一次性下载了 6600 多张照片,200 个视频都成功了,说明这个插件还是很稳定的。

结语
青春是一场回忆,照片是承载的工具,也许在未来的时间中,我们看见照片,又想起了当年的懵懂青涩时光,愿前行,友人在。
备注说明:
插件来自于项目:QQ空间导出助手
python_测试_异步库插件asyncio
在python的测试中,如果实际的代码中有异步的代码,如果单纯的调用代码是会出现报错的问题。
需要在测试代码中添加插件pytest-asyncio,这是一个专注于进行异步测试的pytest的插件。
1 安装
根据官网的连接:pytest-asyncio · PyPI
在终端下载对应的库: $ pip install pytest-asyncio
在测试代码方法上添加注解: @@pytest.mark.asyncio
2 使用
具体的使用办法可以参见以下代码:
@pytest.mark.asyncio
async def test_some_asyncio_code():
res = await library.do_something()
assert b"expected result" == res
3 案例
在不同的测试场景中,都是能使用到插件的。
3.1 在同一事件loop中运行class中的所有测试
所有测试都可以通过使用pytest.mark.asyncio(scope =“ class”)标记在同一事件循环中运行。通过使用Asyncio标记作为类装饰器,可以很容易地实现这一点。
import asyncio
import pytest
@pytest.mark.asyncio(scope="class")
class TestInOneEventLoopPerClass:
loop: asyncio.AbstractEventLoop
async def test_remember_loop(self):
TestInOneEventLoopPerClass.loop = asyncio.get_running_loop()
async def test_assert_same_loop(self):
assert asyncio.get_running_loop() is TestInOneEventLoopPerClass.loop
3.2 在同一事件loop中运行module中的所有测试
所有测试都可以通过使用pytest.mark.asyncio(scope =“ module”)标记在同一事件循环中运行。通过向您的模块添加pytestmark语句可以轻松实现这一点。
import asyncio
import pytest
pytestmark = pytest.mark.asyncio(scope="module")
loop: asyncio.AbstractEventLoop
async def test_remember_loop():
global loop
loop = asyncio.get_running_loop()
async def test_assert_same_loop():
global loop
assert asyncio.get_running_loop() is loop
3.3 在同一事件loop中运行包装中的所有测试
所有测试都可以通过使用pytest.mark.asyncio(scope =“ package”)标记在同一事件循环中。将以下代码添加到测试包的__init__.py:
请注意,此标记不会传递给子弹中的测试。子包构成了自己的单独包装。
import pytest
pytestmark = pytest.mark.asyncio(scope="package")
3.4 在同一事件循环中进行会话中的所有测试
所有测试都可以通过使用pytest.mark.asyncio(scope =“ session”)标记在同一事件循环中运行。标记所有测试的最简单方法是通过pytest_collection_modifyitems挂钩在您的测试套件的根文件夹中的conftest.py。
import pytest
from pytest_asyncio import is_async_test
def pytest_collection_modifyitems(items):
pytest_asyncio_tests = (item for item in items if is_async_test(item))
session_scope_marker = pytest.mark.asyncio(scope="session")
for async_test in pytest_asyncio_tests:
async_test.add_marker(session_scope_marker, append=False)
3.5 使用不同的事件循环测试
参数化event_loop_policy灯具参数参数所有异步测试。下面的示例会导致所有异步测试多次运行,一次在固定框架参数中为每个事件循环运行:
import asyncio
from asyncio import DefaultEventLoopPolicy
import pytest
class CustomEventLoopPolicy(DefaultEventLoopPolicy):
pass
@pytest.fixture(
scope="session",
params=(
CustomEventLoopPolicy(),
CustomEventLoopPolicy(),
),
)
def event_loop_policy(request):
return request.param
@pytest.mark.asyncio
async def test_uses_custom_event_loop_policy():
assert isinstance(asyncio.get_event_loop_policy(), CustomEventLoopPolicy)
3.6 events事件
参数化event_loop_policy 参数参数所有异步测试。下面的示例会导致所有异步测试多次运行,一次在固定框架参数中为每个事件循环运行:
如果您只希望测试的一个子集与不同的事件循环一起运行,则可以选择将fixture的范围限制为包、模块或类。
import asyncio
from asyncio import DefaultEventLoopPolicy
import pytest
class CustomEventLoopPolicy(DefaultEventLoopPolicy):
pass
@pytest.fixture(
scope="session",
params=(
CustomEventLoopPolicy(),
CustomEventLoopPolicy(),
),
)
def event_loop_policy(request):
return request.param
@pytest.mark.asyncio
async def test_uses_custom_event_loop_policy():
assert isinstance(asyncio.get_event_loop_policy(), CustomEventLoopPolicy)
3.7 如何对uvloop进行测试
RedeFinig event_loop_policy固定装置将参数所有异步测试。以下示例会导致所有异步测试多次运行,一次在固定夹参数中为每个事件循环进行一次:替换您的conftest.py中的默认事件循环策略:
如果您只希望使用UVloop运行测试的子集,则可以选择将固定装置的范围限制为包装,模块或类。
import pytest
import uvloop
@pytest.fixture(scope="session")
def event_loop_policy():
return uvloop.EventLoopPolicy()
3.8 如何判断函数是不是为异步
使用pytest_asyncio.is_async_item来确定测试项目是否是异步和由pytest-assyncio管理的。
from pytest_asyncio import is_async_test
def pytest_collection_modifyitems(items):
for item in items:
if is_async_test(item):
pass
4 注意
这个插件也有自己的问题:
它不支持标准联合库的测试类。建议用户使用UnitTest.isolatedAsynciotestcase或异步框架(例如异步)。
本文作者:redtea 红茶的博客
本文链接:https://redtea.top/16964281020029.html
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
TypeScript的严格语法限制解决方案
在进行vue的开发中,在写ts文件时候,遇到有这么一个报错。经过查阅资料和实际进行解决,问题就是出现在了这个语法的严格造成的。
1 报错
具体报错信息如下:

2 缘由
更严格的类属性检查
TypeScript 2.7引入了一个新的控制严格性的标记 --strictPropertyInitialization
使用这个标记会确保类的每个实例属性都会在构造函数里或使用属性初始化器赋值。 在某种意义上,它会明确地进行从变量到类的实例属性的赋值检查
3 解决办法
找到文件中的tsconfig.json配置文件,增加或者修改配置 将严格初始初始化属性去掉
"strictPropertyInitialization": false,

参考链接 :
本文作者:redtea 红茶的博客
本文链接:https://redtea.top/16964281020029.html
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
nginx报错413的解决流程
最近在处理项目问题的时候,遇到了有这么一个有趣的问题,不像其他的报错401、502、500 等,这直接报错了413,这在开发中是常见有不常见的一个状态码,代表着这在使用中有nginx上的问题。
1 nginx报错413
1.1 问题显示:
nginx 出现413 Request Entity Too Large
界面中添加了对应的图纸数据,点击保存,调用更新接口,数据中数据实体过多
1.2 问题排查
- 在网页出现错误的时候,首先就是查看请求日志,做问题复现
- 查询运行日志
1.3 原因
nginx在做代理时候,对实际的数据转发有默认的限制,限制大小为1mb,这个可以在配置文件中进行修改
1.4 解决办法
- 找到nginx配置文件 一般默认的路径是在
/etc/nginx/nginx.conf - 使用vi或者vim命令打开文件进行修改 ,英文模式下,按住i键进入编辑模式
- 找到其中的http{}模块,模块中添加
client_max_body_size 20m;,数字可以根据实际情况自定义,esc退出编辑,:wq,退出保存数据 - 重启nginx ,
sudo systemctl restart nginx
1.5 附录
pgsql中查询数据大小:
SELECT id, DATA->>'name' AS filename , length(DATA::TEXT)/ 1024 AS leMB
FROM tablename
WHERE username= 'admin'
ORDER BY leMB DESC ;
修改参数:

结语
在遇到问题的时候,不着急,先看看报错日志,确定问题的位置,更好的能解决问题。
本文作者:redtea 红茶的博客
本文链接:https://redtea.top
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。

语雀和速度赛跑的8小时,我们学习到了什么?
2023年10 月 23 日 14 时左右,蚂蚁集团旗下的在线文档编辑与协同工具语雀发生服务器故障,在线文档和官网目前均无法打开。
事情虽然已经过去了有几天,现在回过头来看整个事情,梳理这其中的一些关键点,看看哪些是能在其中学习到一些知识的。
1 简述整个事件
从时间线上分析:
- 14:07 数据存储运维团队收到监控系统报警,定位到原因是存储在升级中因新的运维工具 bug 导致节点机器下线;
- 14:15 联系硬件团队尝试将下线机器重新上线;
- 15:00 确认因存储系统使用的机器类别较老,无法直接操作上线,立即调整恢复方案为从备份系统中恢复存储数据;
- 15:10 开始新建存储系统,从备份中开始恢复数据,由于语雀数据量庞大,此过程历时较长;
- 19:00 完成数据恢复,同时为保障数据完整性,在完成恢复后,用时 2 个小时进行数据校验;
- 21:00 存储系统通过完整性校验,开始和语雀团队联调。
- 22:00 恢复语雀全部服务,用户所有数据均未丢失。
这些内容梳理在语雀官方的故障公告中已经有提及到的:
[!note] 这是公告链接:https://mp.weixin.qq.com/s/WFLLU8R4bmiqv6OGa-QMcw
2 语雀的处理思考
这次的宕机,给作为技术人员,运营人员,以及个人都会有不同的思考。
在技术上的具体宕机的细节,其实外人无从知晓,不过从故障的公告中,能看到语雀团队在技术上的一些细节。
以下是关于语雀公告中提及到的他们的解决方案:
1、升级硬件版本和机型,实现离线后的快速上线。该措施在本次故障修复中已完成;
2、运维团队加强运维工具的质量保障与测试,杜绝此类运维 bug 再次发生;
3、缩小运维动作灰度范围,增加灰度时间,提前发现 bug;
4、从架构和高可用层面改进服务,为语雀增加存储系统的异地灾备。
在这个公告中, 其实能看到的几个解决方案,也是在技术实现和运营中经常会使用到的。
升级硬件的处理。在测试开发环境或者是前期的用户体量比较小的时候,大多是觉得基本的硬件能满足条件就行,基于研发成本和维护成本,大概率不会将硬件的配置升级的很高,去应对可能不会经常出现的事故。
在测试和BUG寻找上,特意有提及到了两种改进的意见。作为开发,经常也会遇见语雀中的形似问题,自己开发环境,测试环境都是能正常运行的,实际上到了生产环境上,各种问题就层出不穷,只能说现实的环境远比理想更加的恶劣。
对此来说,也正如语雀那样,通过在测试阶段更多的增加更多对现实生产环境的模拟,更早的将问题暴露出来,及时解决,避免在生产中造成更大的问题。
除开对硬件和问题流程的优化上,另外一个对技术和资金要求比较大点就是,在软件技术层上的优化。 对于这样一个用户和数据量比较巨大的成熟软件里说,想要直接对技术上进行大的重构 ,基本还是比较困难的,毕竟牵一发而动全身,所涉及到的方方面面都比价多。不可能是一朝一夕就能完成的,是需要在一定的技术能力和时间的支撑下才能完成。相信,以这个团队的能力来说,未来还是很快就能实现的,
人无完人,金无赤足。同理,任何一个软件都会存在一些不可知的BUG,也会出现未知错误,没有办法能根治的。
更多的能考虑到可能发生的问题,提前感知处理,站在用户的角度去实际使用体验软件技术带来的便利性,增加更多人在使用中的体验感。
3 事后的补偿
既然,问题发生了,给用户也带来了困扰,必然会有一些机制或者补偿去让更多是人满足。
语雀团队的处理就是一个字,砸钱,营销到让你满意。针对这次发生的错误直接补偿6个月会员。这可是真不少的,很多C端软件发生错误是没有或者只有很少的补偿的。
可以说,这六个月的会员让大部分人都满意的,不少网友甚至希望每年都来上那么一两次这样的事故,毕竟谁不希望能白白获得福利呢。
还有在另外一个方面来说,这种大方的行为,变相的将事故作为了一个营销点,更多的人了解了语雀,获得的一定的用户增长。
4 关于这个事情的思考
对于普通人来说,这样的事情能带给人们的思考有那么几点:
4.1 一是一定做好本地和云端同步的备份
云端协同,固然是有能很便捷,在任何地方都是能查看处理的。一个很大的弊端是一但这个服务出现问题,损失的不仅仅只是资料,更有可能会耽误很多事情,造成直接或者间接的经济损失。
这时候,多端备份,本地化的重要性就体现出来了,云端出现了问题还有本地的,A机器出了问题,还有B机器的,就是不怕出问题。
4.2 二是出现问题不可怕
确实的,出现了问题,其实不可怕的。只要能积极的面对问题,寻找合适待解决方案去解决问题,并及时告知与之相关的人员,大家心里都有底。
很多时候,可怕的就是出现了问题,隐瞒出题,大家没有了知情权,就蒙在了鼓里。等到有一天,大家就会突然发现原来自己曾经是被欺骗过了,那种感觉会让人很不舒服。
4.3 三是真诚
突然脑子里就想起了这个词,联系语雀这个事情,总的来看,各个方面都还挺真诚的。
从出事情开始,语雀就在微博上更新发现问题,真诚的给大家足够的知情权。
此后也是在一直更新处理的进度,让大众能看到处理的希望。
最后是拿故障公告,不仅写出了事情的原因,详细的解决方案,更是还给了用户福利。这些点就是真诚,很打动人,这在这个社会上算是比较少见的,也是收获了一只好评。
所以真诚就是必杀技!
说了那么多,吃瓜是娱乐,如果能将事情结合自己的工作生活,给自己带来启示和发展,这就是吃瓜的终极奥义吧。
本文作者:redtea 红茶的博客
本文链接:https://redtea.top/
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
lombok boolean属性缺失get set 方法
场景:使用Lombok时,发现对于
解决方案:使用包装类型即可Boolean
使用的场景
在实际的项目中,有使用到lombok插件,这个插件能减少写代码的时候,不断的习重复的get、set方法,让代码变得简洁。
问题
俗话说,有便利的地方,必然会牺牲一部分东西作为交换的,同样,在在这个lombok也是如此,在进行相关操作的时候。
有遇到是boolean基础属性,会无法调用getset方法。
这是由于boolean的属性以isXXX开头时,会导致Lombok不会为该属性生成getXXX和setXXX方法,这是由于Lombok特性所致,具体原因可以见其官网说明。
解决方法
有两种办法进行解决:
一是使用包装类型Boolean。
二是手动对boolean设置get set方法。
结语
代码的世界是有趣的,时常会出现一些有趣的BUG,让人防不胜防,只能不断的精进自己,去了解他们。
本文作者:redtea 红茶的博客
本文链接:https://redtea.top
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
Scala语言函数式编程数组转换错误
在使用scala函数式编程语言写对应的代码的时候,使用数组相关的知识,出现了转换的错误,不能正确输出对应的数组内容。
1 问题:
代码:
//多维数组
val a17 = Array.ofDim[String](2, 2)
for (i <- 0 to 1) {
for (j <- 0 to 1) {
a17(i)(j) = (i + j).toString
}
}
println("a17多维数组是:" + a17)
//正确方式
println("a17的正常显示数组为:" + stringOf(a17))
输出的结果是:
a17多维数组是:[[Ljava.lang.String;@77b52d12
对这个结果的解释是:
“[” 表示一维数组
"[["表示二维数组
"L"表示一个对象
"java.lang.String"表示对象的类型
"@"后面表示该对象的HashCode
2 解决办法:
1、直接在对应的数组后面跟上一个方法,Array.toString(x),就能将对应的数组显示出来了。
2、导入一个打印美化包
import scala.runtime.ScalaRunTime.stringOf
在引包以后,调用stringOf(x) 方法,就能实现对数组的打印了 ,这个方法对多维数组也是生效的。
3、使用mkString 方法,这个对一维数组是有效的,多维数组不能生效,使用方法 x.mkString(",")
本文作者:redtea 红茶的博客
本文链接:https://redtea.top/16964281020029.html
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
asar文件的解压读取
在实际开发中,有这样子的需求,就是需要解压asar结尾的文件。这里会涉及到两个基础环境的安装,node.js和npm有对应的配置。
在本次的实验中使用的配置如下:
node版本:18
npm版本:10.0.1
1 网上教程
app.asar文件是Electron加密打包时的中间产物,electron.exe调用resources文件夹下的app.asar从而实现不用解压缩而直接读取文件内容的高效。
在网上的一些教程中,对asar文件的解压和打包主要是执行以下命令:
1、安装asar
npm install -g asar
2、cmd窗口中解压文件
asar extract app.asar ./app
3、没有表示成功
在文件夹系统中可以查看
2 报错提示
执行安装命令中,实际会报错以下消息:
npm WARN deprecated [email protected]: Please use @electron/asar moving forward. There is no API change, just a package name change
原因是在新版本的框架中,已经有包含了asar的支持,不需要在额外下载对应的模块,只需要更更换执行的命令即可。
根据警告消息所示,官方建议改用 @electron/asar。这是一个针对 Electron 应用程序中的数据和文件管理的模块,它支持读取和打包应用内的文件,可以在命令行中使用。 您可以按照下面的步骤来更新 asar 版本:
1. 卸载旧版 asar: `npm uninstall asar`
2. 安装新版 @electron/asar: `npm install -g @electron/asar`
3. 使用 @electron/asar 打包应用程序: `npx asar pack <app_directory> <output_file>`
4. 读取 asar 文件: `npx asar extract <input_file> <output_directory>`
3 执行成功
按照上一步的操作,更换了执行命令以后,就能正常把文件解压。
所以,在执行软件的使用中,有时候需要注意版本更换以后带来的问题,及时调整对应的执行和使用命令。
本文作者:redtea 红茶的博客
本文链接:https://redtea.top
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
Apache Log4j Java 日志组件详解
前言:
Log4j 是 Apache 的一个开放源代码项目,通过使用 Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI 组件、甚至是套接口服务 器、NT 的事件记录器、UNIX Syslog 守护进程等;
我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
最令人感兴趣的就 是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
1 主要的组件
Log4j有三个主要的组件:
loggers: 负责捕获日志信息 ,即日志纪录器,控制日志的输出以及输出级别(JUL做日志级别用Level类)
appenders: 负责输出信息到不同的目的地 ,即输出日志到指定的地方
layouts: 负责使用不同的样式输出日志,即格式化日志
1.1 日志级别
例如DEBUG、INFO、WARN、ERROR…级别是分大小的,
DEBUG < INFO < WARN < ERROR,可以用来代指该日志的重要程度,可以由这个来设置对应的。

1.2 日志输出位置
日志输出的位置是由参数appender决定的,根据不同的参数设定,可以将日志文件自定义输出到控制台、文件中等
- 常用Appenders:
- ConsoleAppender
将日志输出到控制台
- FileAppender
将日志输出到文件中
- DailyRollingFileAppender (根据天数来对新日志文件的创建)
将日志输出到一个日志文件,并且每天输出到一个新的文件
- RollingFileAppender (根据大小来对新日志文件的创建)
将日志信息输出到一个日志文件,并且指定文件的尺寸,当文件大小达到指定尺寸时,会自动把文件改名,同时产生一个新的文件
- JDBCAppender
把日志信息保存到数据库中
1.3 日志格式化
在日志输出中,用户可以根据自己的实际需求,把对应的日志按照自己的想法和格式进行输出,在Layouts给用户提供四种日志输出样式。
-
根据HTML样式
-
自由指定样式
-
包含日志级别与信息的样式
-
包含日志时间、线程、类别等信息的样式
-
常用Layouts:
- HTMLLayout
格式化日志输出为HTML表格形式 - SimpleLayout
简单的日志输出格式化,打印的日志格式如默认INFO级别的消息 PatternLayout
最强大的格式化组件,可以根据自定义格式输出日志,如果没有指定转换格式, 就是用默认的转换格式
- HTMLLayout
案例使用:
- %m 输出代码中指定的日志信息
- %p 输出优先级,及 DEBUG、INFO 等
- %n 换行符(Windows平台的换行符为 “\n”,Unix 平台为 “\n”)
- %r 输出自应用启动到输出该 log 信息耗费的毫秒数
- %c 输出打印语句所属的类的全名
- %t 输出产生该日志的线程全名
- %d 输出服务器当前时间,默认为 ISO8601,也可以指定格式,如:%d{yyyy年MM月dd日 HH:mm:ss}
- %l 输出日志时间发生的位置,包括类名、线程、及在代码中的行数。如:Test.main(Test.java:10)
- %F 输出日志消息产生时所在的文件名称
- %L 输出代码中的行号
- %% 输出一个 “%” 字符
可以在 % 与字符之间加上修饰符来控制最小宽度、最大宽度和文本的对其方式。
如:
%5c 输出category名称,最小宽度是5,category<5,默认的情况下右对齐
%-5c 输出category名称,最小宽度是5,category<5,"-"号指定左对齐,会有空格
%.5c 输出category名称,最大宽度是5,category>5,就会将左边多出的字符截掉,<5不
会有空格
%20.30c category名称<20补空格,并且右对齐,>30字符,就从左边交远销出的字符截掉
1.4 项目使用情况说明:
输出日志使用是DailyRollingFileAppender,会每天生成日志。
==优化点:== 目前项目中有实时库的存在,写日志会很多,导致当日日志文件也会很大,查看日志的时候会存在打开困难的情况,可以考虑使用按大小创建日志比如300MB创建一个新的,给一个新的命名。
输出级别:
目前的级别是在debug info warn error 这几个级别中
分为两个目录写日志 debug_log 、 error_log 这两个,error中写的是info最小的,debug中写的是debug最小的。
==优化点:== 两个日志写入内容有重复,
1、可以在控制层对日志进行整理处理,分别在不同的地方写入不同的日志。
2、规划重要耗时做debug处理,其他警告、报错信息放到error中去。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration PUBLIC
"-//APACHE//DTD LOG4J 1.2//EN" "http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/xml/doc-files/log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="A_ERROR" class="org.apache.log4j.DailyRollingFileAppender">
<param name="Append" value="true"/>
<param name="Encoding" value="UTF-8" />
<param name="File" value="/var/opt/meta/webapp/logs/meta_error.log"/>
<param name="DatePattern" value="'.'yyyyMMdd"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{yyyy/MM/dd HH:mm:ss} [%-5p] - %m%n"/>
</layout>
<filter class="org.apache.log4j.varia.LevelRangeFilter">
<param name="LevelMin" value="info"/>
<param name="LevelMax" value="error"/>
<param name="AcceptOnMatch" value="true"/>
</filter>
</appender>
<appender name="A_DEBUG" class="org.apache.log4j.DailyRollingFileAppender">
<param name="Append" value="true"/>
<param name="Encoding" value="UTF-8" />
<param name="File" value="/var/opt/meta/webapp/logs/meta_debug.log"/>
<param name="DatePattern" value="'.'yyyyMMdd"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{yyyy/MM/dd HH:mm:ss} [%-5p] - %m%n"/>
</layout>
<filter class="org.apache.log4j.varia.LevelRangeFilter">
<param name="LevelMin" value="debug"/>
<param name="LevelMax" value="error"/>
<param name="AcceptOnMatch" value="true"/>
</filter>
</appender>
<!-- framework logger -->
<logger name="java.sql">
<level value="warn" />
</logger>
<logger name="org.mybatis">
<level value="warn" />
<!-- <appender-ref ref="STDOUT" />-->
</logger>
<logger name="org.apache">
<level value="warn" />
</logger>
<logger name="org.springframework">
<level value="warn" />
</logger>
<!-- the root logger -->
<root>
<level value="all" />
<appender-ref ref="A_ERROR" />
<appender-ref ref="A_DEBUG" />
</root>
</log4j:configuration>
参考链接 :
【精选】日志框架(2) : Log4j介绍及使用_log4j日志的使用-CSDN博客
log4j配置详解 log4j中文文档_log4j官方文档-CSDN博客
本文作者:redtea 红茶的博客
本文链接:https://redtea.top版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。



obsidan中附件管理的原则和处理方案
在做笔记的过程中,不可避免的会涉及到图片的分享。是选择将图片直接放在本地,还是将文件通过图床的方式进行分享、本地只存图片连接。
本文将结合这两种方式,进行分析,说说我自己的看法和实践经验,至少这两种方案都有使用过。
1 纯本地存储
当初使用这个本地储存的原因,也是刚由其他笔记转为使用obsidan,看中的就是能将笔记放在本地,能确保自己的笔记真属于自己。不会因为,使用其他平台服务器故障,宕机的情况下笔记丢失。
在这个前提下,实际就能做本地图片附件的管理,重要的就是能将图片重命名和放下特定位置下做管理,这就是解决本地存储的最大问题。
1.1 解决这个问题主要就有两个步骤:
一是对obsidan软件本身设定附件文件夹,设置好对应的附件文件夹的路径,这样能保证所有的图片都能放在这个路径下。
二是使用插件paste image rename , 进行如图设置后,就能进行自动重命名了,方便后期查找。


2 云端存储
云端存储,能实现的最大方便之处在于,本地没有了太多的图片文件,不会再影响obsdian的加载速度。
使用这种方式有很多的方案可以实现,总的方向就是存储仓库+图床工具+obsdian插件。
2.1 存储仓库的选择
在存储仓库的选择上,其实还是蛮多的。就比如,如果你是程序员,可以尝试GitHub 、gitee这种,平时经常在使用的,也不用花费任何费用,学习成本也相对较低。
其次,可以选择,腾讯云、阿里云、华为云等的oss存储技术,简单快捷,之间简单配置下就能使用,不用折腾太多的技术。它的优点就是简单快捷,费用也相对便宜,一年几十块就能搞定。
再有就是相对花费高或者学习成本高的技术手段,直接上nas系统,将自己的储存放在自己的私有服务器中。还有就是拥有一台自己的服务,搭建属于自己的文件系统,在这个文件系统中做文件内容的管理,这种就会要求使用者有一定的技术能力,能在使用过程中,解决遇到的各种问题。

仓库的选择还是相对重要,一旦选择,意味着接下来很长一段时间都会在使用这个仓库,只要这个仓库的内容多起来以后,想要做迁移,其实还是会存在很大的困难的。
所以,在开始的时候,可以考虑好自己想要的仓库,做好未来两三年都会使用这个仓库的决定,以减少不必要的麻烦。
2.2 图床工具的选择
这个也是在做云端文件存储中很重要的一个环节。一般分为在线的小图床工具和比较知名的有专属客户端的图床工具。
以前也用过在线的图床工具,使用了一段时间,发现其实还是有不少不方便的地方,在每一次上传图片的时候,需要自行登陆网站,上传好对应的图片以后,复制上传好的链接,在填写到自己的文章中,这种的效率实际上来说是增加了一个工作流的过程,拖慢了工作效率。
后面发现还有专属客户端的工具,真香。能结合自己现有的工作流去快速的增加工作效率,真正提升自己的幸福感。就简单的例子,在对软件做好配置以后,能直接截图实现图片自动上传,上传后的链接自动保存剪贴板,直接ctrl+v就能使用,不可谓不快。
2.3 obsidan插件
云端存储这个过程中,在配合使用obsdian的相关插件使用,可定会使用到的就是这个图片上传的插件image auto plugin,能实现图片的自动上传。

3 本地+云端的存储形式
由于在做笔记的时候涉及到的图片多是一些截图或者不是很大的图片,并且是希望更多的将图片放在本地做管理,这样更加保险一点。
这种做法的核心是,把所有的图片放在obsdian的特定文件夹下,结合给图片修改名字的插件paste image rename ,实现将文件名字和文章的标题结合起来,方便后期查找。
需要使用到云端储存的图片,比如发布文章的时候 ,可以将单独把图片上传到云端去。
在这个方案下,既可以确保笔记的安全性,也能保障在写文章的时候足够的便捷,随时分享。
4 结语
笔记系统中附件的管理,从来就没有谁好谁坏之分,只有最适合自己的才是更好的。也只有在实践中,不停地去探索,才能找到适合自己的方式。
折腾啊!就是快乐!!
本文作者:redtea 红茶的博客
本文链接:https://redtea.top
版权声明:本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可,非商业转载及引用请注明出处(作者、原文链接),商业转载请联系作者获得授权。
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.